数据湖 vs 数据仓库:现代数据栈如何选择
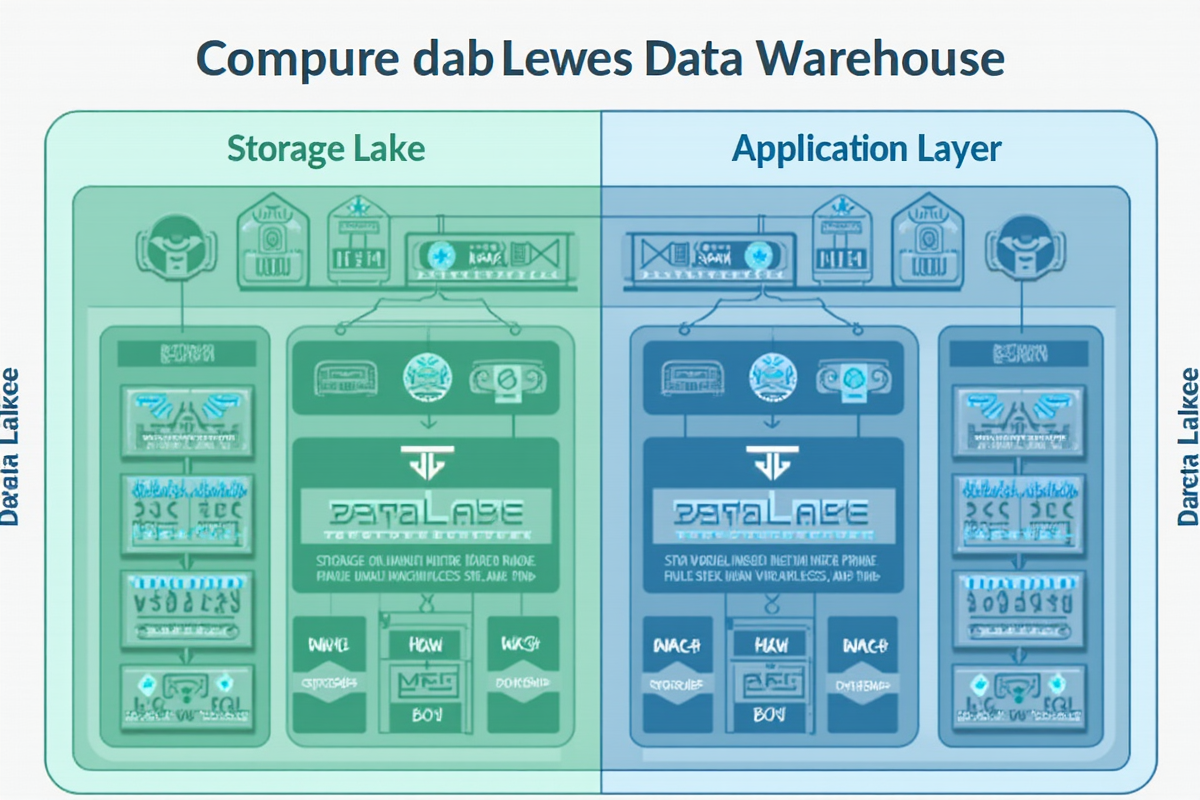
数据湖 vs 数据仓库:现代数据栈如何选择
引言
在数据驱动的时代,企业面临着海量的数据存储和处理需求。选择合适的数据架构方案成为技术决策的核心挑战。数据湖(Data Lake)和数据仓库(Data Warehouse)作为两大主流数据架构,各自承载着不同的业务场景和技术目标。
数据架构选型的重要性:
❌ 错误的架构选型会导致:
- 数据治理混乱
- 查询性能低下
- 存储成本失控
- 数据分析能力受限
✅ 正确的架构选型可以:
- 提升数据利用效率
- 降低运营成本
- 加速业务洞察
- 支持未来扩展
数据架构演进历程:
1990s: 传统数据仓库
↓ (数据量增长,结构复杂)
2010s: 大数据数据湖
↓ (实时性、计算需求提升)
2020s: 数据湖仓一体化 (Data Lakehouse)
↓ (混合负载、多云架构)
未来:智能数据平台
本教程将从原理到实践,全面对比数据湖与数据仓库的异同,帮助你根据业务需求做出明智的架构选择。
适用读者: 数据工程师、数据架构师、技术决策者
—
数据仓库详解
1. 概念与起源
数据仓库(Data Warehouse) 是由 Bill Inmon 在 1990 年代提出的概念,专为分析型工作负载设计。其核心思想是将来自不同来源的结构化数据,经过清洗、转换、集成后,存储在一个统一的、优化的存储层中。
核心特征:
- ✅ 面向主题:按业务主题组织数据(如销售、客户、产品)
- ✅ 集成性:统一数据格式和标准
- ✅ 时变性:记录历史数据变化
- ✅ 非易失性:数据一旦写入,只读不写
2. 经典架构
┌─────────────────────────────────────────────────────────────┐
│ 数据源层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ MySQL │ │ Oracle │ │ Kafka │ │ 日志 │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
└───────┼─────────────┼─────────────┼─────────────┼─────────┘
│ │ │ │
▼ ▼ ▼ ▼
┌─────────────────────────────────────────────────────────────┐
│ 数据集成层 (ETL) │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 抽取 (Extract) → 转换 (Transform) → 加载 (Load) │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 数据仓库层 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 维度模型:星型/雪花模型 │ │
│ │ - 事实表 (Fact Table) │ │
│ │ - 维度表 (Dimension Table) │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 数据服务层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ BI 工具 │ │ 报表 │ │ 可视化 │ │ 分析 │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────┘
3. 技术栈对比
| 厂商 | 代表产品 | 特点 | 适用场景 |
|---|---|---|---|
| 传统 | Oracle, Teradata, Netezza | 商业软件,高性能 | 大型企业核心业务 |
| 云原生 | Snowflake, Redshift, BigQuery | 弹性扩展,按需付费 | 云环境,混合负载 |
| 开源 | Apache Hive, Presto | 灵活定制,成本可控 | 自建大数据平台 |
4. 优势与局限
优势:
✅ 数据质量高(ETL 严格清洗)
✅ 查询性能优秀(列式存储,预聚合)
✅ 数据一致性保证(Schema-on-Read)
✅ 成熟的安全性和权限控制
✅ 适合 SQL 分析工作负载
局限:
❌ 结构化数据为主,非结构化支持弱
❌ 存储成本较高(压缩率低)
❌ 扩展性受限(传统方案)
❌ ETL 流程复杂,开发周期长
❌ 实时性较差(批处理为主)
—
数据湖详解
1. 概念与起源
数据湖(Data Lake) 由 James Dixon 在 2010 年代提出,基于 Hadoop 生态系统构建。其核心理念是存储原始数据,延迟结构化处理(Schema-on-Read),支持更灵活的数据探索和分析。
核心特征:
- ✅ 原始数据:存储未经处理的原始格式
- ✅ 任意模式:支持结构化、半结构化、非结构化
- ✅ Schema-on-Read:查询时定义结构
- ✅ 低成本存储:对象存储,价格低廉
2. 经典架构
┌─────────────────────────────────────────────────────────────┐
│ 数据源层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 应用日志 │ │ IoT 设备 │ │ 社交媒体 │ │ CSV/JSON │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
└───────┼─────────────┼─────────────┼─────────────┼─────────┘
│ │ │ │
▼ ▼ ▼ ▼
┌─────────────────────────────────────────────────────────────┐
│ 数据摄入层 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 批量导入 (Sqoop, Flume) / 流式导入 (Kafka) │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 数据存储层 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 对象存储 (S3, ADLS, GCS) │ │
│ │ 或 HDFS │ │
│ │ - 原始层 (Raw) │ │
│ │ - 清洗层 (Cleansed) │ │
│ │ - 加工层 (Curated) │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 数据处理层 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 批处理:Spark, Hive │ │
│ │ 流处理:Spark Streaming, Flink, Kafka Streams │ │
│ │ 查询引擎:Presto, Trino, Athena │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 数据服务层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ ML 训练 │ │ 数据科学 │ │ 探索分析 │ │ API 服务 │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────┘
3. 技术栈对比
| 组件 | 开源方案 | 云托管方案 |
|——|———-|————|
| 存储 | HDFS, S3 | AWS S3, Azure ADLS, GCS |
| 计算 | Spark, Flink, Hive | EMR, Databricks, Dataproc |
| 查询 | Trino, Presto | Athena, Redshift Spectrum |
| 格式 | Parquet, ORC | Parquet, Delta Lake, Iceberg |
| 治理 | Apache Atlas | AWS Glue Data Catalog |
4. 优势与局限
优势:
✅ 存储成本低(对象存储价格仅为云盘 1/10)
✅ 支持任意数据类型(结构化、半结构化、非结构化)
✅ 灵活的数据探索(Schema-on-Read)
✅ 易于扩展(横向扩展无限)
✅ 支持机器学习数据准备
局限:
❌ 数据质量难以保证(缺少 Schema 约束)
❌ 查询性能较差(尤其是复杂查询)
❌ 数据治理困难(数据沼泽风险)
❌ ACID 事务支持弱(传统方案)
❌ 安全控制相对复杂
—
核心对比
1. 技术对比表
| 对比维度 | 数据仓库 | 数据湖 |
|———-|———-|——–|
| 数据结构 | 结构化 | 任意(结构化/半结构化/非结构化) |
| 存储格式 | 列式存储(列族) | 多格式(CSV、JSON、Parquet、图片等) |
| Schema 策略 | Schema-on-Write(写入时定义) | Schema-on-Read(读取时定义) |
| 存储成本 | 高(专有存储) | 低(对象存储) |
| 查询性能 | 高(预优化) | 中到低(取决于查询引擎) |
| 数据新鲜度 | T+1 为主 | 实时/近实时 |
| 扩展性 | 有限 | 无限水平扩展 |
| 数据治理 | 成熟完善 | 发展中等 |
| 计算存储耦合 | 紧密耦合 | 解耦 |
| 适用负载 | BI、报表 | 探索分析、ML、实时处理 |
2. 性能对比实验
-- 场景:查询 100 亿条销售记录,按地域分组聚合
-- 数据仓库(Snowflake/Redshift)
SELECT
region,
SUM(amount) as total_sales,
COUNT(*) as order_count
FROM sales_fact
WHERE sale_date >= '2024-01-01'
GROUP BY region;
-- 结果:响应时间 2-5 秒
-- 查询计划自动优化
-- 使用预聚合索引
-- 数据湖(Spark on S3)
SELECT
region,
SUM(amount) as total_sales,
COUNT(*) as order_count
FROM sales_table
WHERE sale_date >= '2024-01-01'
GROUP BY region;
-- 结果:响应时间 15-30 秒
-- 需要手动优化分区
-- 数据扫描量大
3. 成本对比模型
假设:1PB 数据存储,年查询量 100 万次
数据仓库方案:
- 存储成本:$150,000/年(专有存储)
- 查询成本:$50,000/年(按扫描量计费)
- 计算成本:$30,000/年
- 总计:$230,000/年
数据湖方案:
- 存储成本:$12,000/年(S3 标准层)
- 查询成本:$3,000/年(Athena/Trino)
- 计算成本:$20,000/年(EMR/Spark)
- 总计:$35,000/年
成本节省:约 85%
—
Lambda 架构与 Kappa 架构介绍
1. Lambda 架构
Lambda 架构 由 Nathan Marz 在 2011 年提出,结合了批处理和流处理的优势。
┌─────────────────────────────────────────────────────────────┐
│ 数据源 │
└────────────────────┬────────────────────────────────────────┘
│
┌────────────┴────────────┐
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ 批处理层 (Batch)│ │ 速度层 (Speed) │
│ - Hadoop/Spark │ │ - Storm/Flink │
│ - 完整历史数据 │ │ - 实时增量数据 │
│ - 精确计算 │ │ - 近似计算 │
└────────┬────────┘ └────────┬────────┘
│ │
│ │
▼ ▼
┌─────────────────────────────────────────┐
│ 服务层 │
│ - 批处理结果 + 流处理结果合并 │
│ - 提供统一的查询接口 │
└─────────────────────────────────────────┘
优势:
- ✅ 兼顾准确性和实时性
- ✅ 容错机制完善
- ✅ 适合复杂计算
劣势:
- ❌ 系统复杂(需要维护两套逻辑)
- ❌ 数据冗余(批流重复计算)
- ❌ 运维成本高
2. Kappa 架构
Kappa 架构 是 Lambda 架构的简化版本,只保留流处理层。
┌─────────────────────────────────────────────────────────────┐
│ 数据源 │
└────────────────────┬────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 消息队列 (Kafka) │
│ - 数据缓冲 │
│ - 消息重放支持 │
└────────────────────┬────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 流处理引擎 (Flink/Spark Streaming) │
│ - 实时计算 │
│ - 状态管理 │
│ - 结果写入(数据仓库/数据湖) │
└────────────────────┬────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 查询服务 (Trino/ClickHouse) │
└─────────────────────────────────────────────────────────────┘
优势:
- ✅ 架构简洁(单一代码库)
- ✅ 维护成本低
- ✅ 实时性好
劣势:
- ❌ 历史数据重放复杂
- ❌ 批处理性能不如 Lambda
- ❌ 状态管理要求高
3. 架构选择建议
选择 Lambda 架构如果:
✅ 需要精确的批处理结果
✅ 历史数据回溯频繁
✅ 计算逻辑复杂
选择 Kappa 架构如果:
✅ 实时性要求高
✅ 数据量中等(<100TB)
✅ 团队规模有限
✅ 流处理逻辑相对简单
---
现代数据栈(Data Lakehouse)的兴起
1. 概念与背景
Data Lakehouse(数据湖仓) 是结合了数据湖和数据仓库优势的新型架构。它保留了数据湖的低成本、灵活性特点,同时引入了数据仓库的 ACID 事务、Schema 管理等能力。
核心特征:
- ✅ 低成本存储:基于对象存储
- ✅ ACID 事务:保证数据一致性
- ✅ 支持 BI 和 ML:统一平台
- ✅ 数据治理:类似数据仓库的治理
- ✅ 性能优化:查询引擎加速
2. 技术实现
┌─────────────────────────────────────────────────────────────┐
│ 存储层(数据湖) │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ AWS S3 / Azure ADLS / GCS │ │
│ │ 文件:Parquet, Delta Lake, Apache Iceberg, Hudi │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 表格式层(Table Format) │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Delta Lake: 增量快照,ACID 事务 │ │
│ │ Iceberg: 时间旅行,模式演化 │ │
│ │ Hudi: Upsert 能力,增量处理 │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 计算层(统一引擎) │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Spark SQL: 批处理 │ │
│ │ Trino/Presto: 交互式查询 │ │
│ │ Flink: 流处理 │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 服务层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ BI 工具 │ │ 数据科学 │ │ ML 训练 │ │ API 服务 │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────┘
3. 主流技术对比
| 技术 | 开发商 | ACID | 时间旅行 | Upsert | 适用场景 |
|------|--------|------|----------|--------|----------|
| Delta Lake | Databricks | ✅ | ✅ | ✅ | 云环境,ML 集成 |
| Apache Iceberg | Netflix | ✅ | ✅ | ✅ | 通用,多云支持 |
| Apache Hudi | Uber | ✅ | ⚠️ | ✅ | 实时处理,Spark 优先 |
| Parquet | Apache | ❌ | ❌ | ❌ | 只读场景 |
4. 优势分析
相比数据仓库:
✅ 存储成本降低 70-80%
✅ 支持任意数据类型
✅ 计算存储解耦
✅ 扩展性更强
✅ 支持实时 Upsert
相比数据湖:
✅ ACID 事务保证
✅ 数据治理更完善
✅ 查询性能提升 5-10 倍
✅ 时间旅行能力
✅ Schema 管理更规范
---
选型指南
1. 场景化选择矩阵
┌─────────────────────────────────────────────────────────────┐
│ 业务需求分析 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 数据类型? │
│ ├─ 主要是结构化数据 → 数据仓库 │
│ └─ 包含非/半结构化 → 数据湖或 Lakehouse │
│ │
│ 查询类型? │
│ ├─ 固定报表/BI 分析 → 数据仓库 │
│ ├─ 探索分析/ML 训练 → 数据湖 │
│ └─ 混合负载 → 数据湖仓 │
│ │
│ 实时性要求? │
│ ├─ T+1 即可 → 数据仓库或批处理数据湖 │
│ └─ 实时/近实时 → 数据湖 + 流处理 │
│ │
│ 预算约束? │
│ ├─ 预算充足 → 商业数据仓库 (Snowflake/Redshift) │
│ └─ 预算有限 → 开源数据湖或 Lakehouse │
│ │
└─────────────────────────────────────────────────────────────┘
2. 详细选型建议
选择数据仓库如果:
✅ 主要使用结构化数据
✅ 固定 BI 报表需求
✅ 对查询性能要求高(秒级响应)
✅ 预算充足(可接受较高成本)
✅ 需要严格的数据治理
✅ SQL 分析为主,ML 需求少
推荐产品:
- 商业:Snowflake, Redshift, BigQuery, Databricks SQL
- 开源:Hive + Presto, ClickHouse
选择数据湖如果:
✅ 包含大量非/半结构化数据
✅ 数据探索和 ML 需求
✅ 需要灵活 Schema
✅ 预算敏感
✅ 数据量巨大(PB 级)
✅ 实时数据处理需求
推荐技术栈:
- 存储:AWS S3, Azure ADLS, GCS
- 计算:Spark, Trino
- 格式:Parquet, ORC
选择数据湖仓如果:
✅ 需要兼顾 BI 和 ML
✅ 需要 ACID 事务
✅ 需要时间旅行功能
✅ 实时和批量混合负载
✅ 追求成本效益
✅ 多云或混合云部署
推荐方案:
- Delta Lake + Databricks
- Apache Iceberg + Trino/Spark
- Apache Hudi + Flink
3. 迁移路径建议
传统数据仓库 → 数据湖仓迁移路径:
阶段 1: 数据湖建设
- 搭建 S3/HDFS 存储层
- 配置 Spark/Trino 计算引擎
- 迁移历史数据到对象存储
阶段 2: 表格式层
- 引入 Delta Lake/Iceberg/Hudi
- 开启 ACID 事务支持
- 配置数据治理工具
阶段 3: 查询优化
- 优化表格式(Z-Order, Indexing)
- 配置查询引擎缓存
- 建立数据血缘管理
阶段 4: 混合使用
- 保留关键报表用传统 DW
- 新场景逐步迁移到 Lakehouse
- 逐步淘汰旧系统
---
实际案例与最佳实践
1. 电商行业案例
某大型电商平台数据架构演进:
2018: 传统数据仓库
┌─────────────────────────────────┐
│ Redshift (50TB 数据) │
│ - BI 报表 │
│ - T+1 分析 │
│ 问题:成本高,ML 数据支持弱 │
└─────────────────────────────────┘
2020: 数据湖建设
┌─────────────────────────────────┐
│ AWS S3 (500TB 数据) │
│ + Spark + Presto │
│ - 支持原始数据存储 │
│ - 支持用户行为分析 │
│ 问题:性能不足,数据质量差 │
└─────────────────────────────────┘
2022: 数据湖仓升级
┌─────────────────────────────────┐
│ Delta Lake on S3 (1PB 数据) │
│ + Spark + Trino + Databricks │
│ - BI 和 ML 统一平台 │
│ - 实时推荐系统 │
│ - 成本降低 60% │
└─────────────────────────────────┘
关键指标:
- 查询性能:2 秒 (DW) → 15 秒 (DL) → 3 秒 (Lakehouse)
- 存储成本:$300K/年 → $50K/年 → $70K/年
- 数据时效:T+1 → 小时级 → 分钟级
2. 金融行业案例
某银行实时风控数据平台:
架构设计:
┌──────────────────────────────────────┐
│ Kafka (流数据源) │
│ - 交易数据 │
│ - 账户操作 │
│ - 用户行为 │
└──────────────┬───────────────────────┘
│
▼
┌──────────────────────────────────────┐
│ Flink (实时处理) │
│ - 实时欺诈检测 │
│ - 风险评分 │
│ - 异常模式识别 │
└──────────────┬───────────────────────┘
│
▼
┌──────────────────────────────────────┐
│ Delta Lake (湖仓存储) │
│ - ACID 事务保证 │
│ - 时间旅行追溯 │
│ - 批量历史分析 │
└──────────────┬───────────────────────┘
│
▼
┌──────────────────────────────────────┐
│ Trino/Presto (查询服务) │
│ - 监管报表 │
│ - 审计分析 │
│ - 风险报告 │
└──────────────────────────────────────┘
业务价值:
✅ 欺诈检测延迟:<100ms (之前 5 分钟)
✅ 监管报表:实时生成 (之前 3 天)
✅ 数据准确性:100% ACID 保证
✅ 成本优化:相比全云 DW 降低 40%
3. 最佳实践
数据治理最佳实践:
1. 统一元数据管理
- 使用统一的数据目录 (如 AWS Glue Catalog)
- 建立数据血缘追踪
- 数据质量监控
- 定义数据质量规则
- 定期数据质量检查
- 异常数据告警
- 权限和安全
- 细粒度权限控制 (列级/行级)
- 数据加密 (存储加密/传输加密)
- 审计日志
- 成本控制
- 冷热数据分离
- 自动数据生命周期管理
- 查询成本监控
性能优化最佳实践:
1. 存储格式优化
✅ 使用列式存储 (Parquet/ORC)
✅ 数据压缩 (Snappy/Zstd)
✅ 分区策略合理 (按月/按天/按地域)
- 查询优化
✅ 使用预聚合表
✅ 避免全表扫描
✅ 利用向量化执行
- 缓存策略
✅ 热点数据缓存
✅ 查询结果缓存
✅ 元数据缓存
---
总结
核心要点回顾
数据仓库:
- ✅ 适合结构化数据、BI 分析
- ✅ 查询性能优秀,治理完善
- ✅ 成本较高,扩展性有限
数据湖:
- ✅ 适合任意数据类型,成本低
- ✅ 扩展性强,灵活度高
- ✅ 查询性能弱,治理难度大
数据湖仓:
- ✅ 结合两者优势
- ✅ ACID 事务 + 灵活存储
- ✅ 当前主流趋势
选型决策树
开始
│
├─ 数据主要是结构化?
│ ├─ 是 → 需要实时性?
│ │ ├─ 是 → 数据湖仓 (Delta Lake/Iceberg)
│ │ └─ 否 → 数据仓库 (Snowflake/Redshift)
│ └─ 否 → 需要 ML/探索分析?
│ ├─ 是 → 数据湖仓
│ └─ 否 → 数据湖 (S3 + Spark)
│
└─ 根据预算调整:
├─ 预算充足 → 商业方案 (Databricks/Snowflake)
└─ 预算有限 → 开源方案 (Iceberg + Trino)
未来趋势
1. 湖仓一体化成为主流
- 数据湖和数据仓库的界限逐渐模糊
- 统一的存储和计算层
- 实时性要求提升
- 实时数据湖仓
- 流批一体处理
- 智能化
- 自动数据优化
- 智能查询优化
- 多云支持
- 跨云数据湖仓
- 混合云架构
---
*本文档最后更新时间:2026 年 04 月 27 日*
*作者:creator | 适合数据工程师和架构师参考*
发表评论