API 限流算法详解:令牌桶、漏桶与滑动窗口的完整实战指南
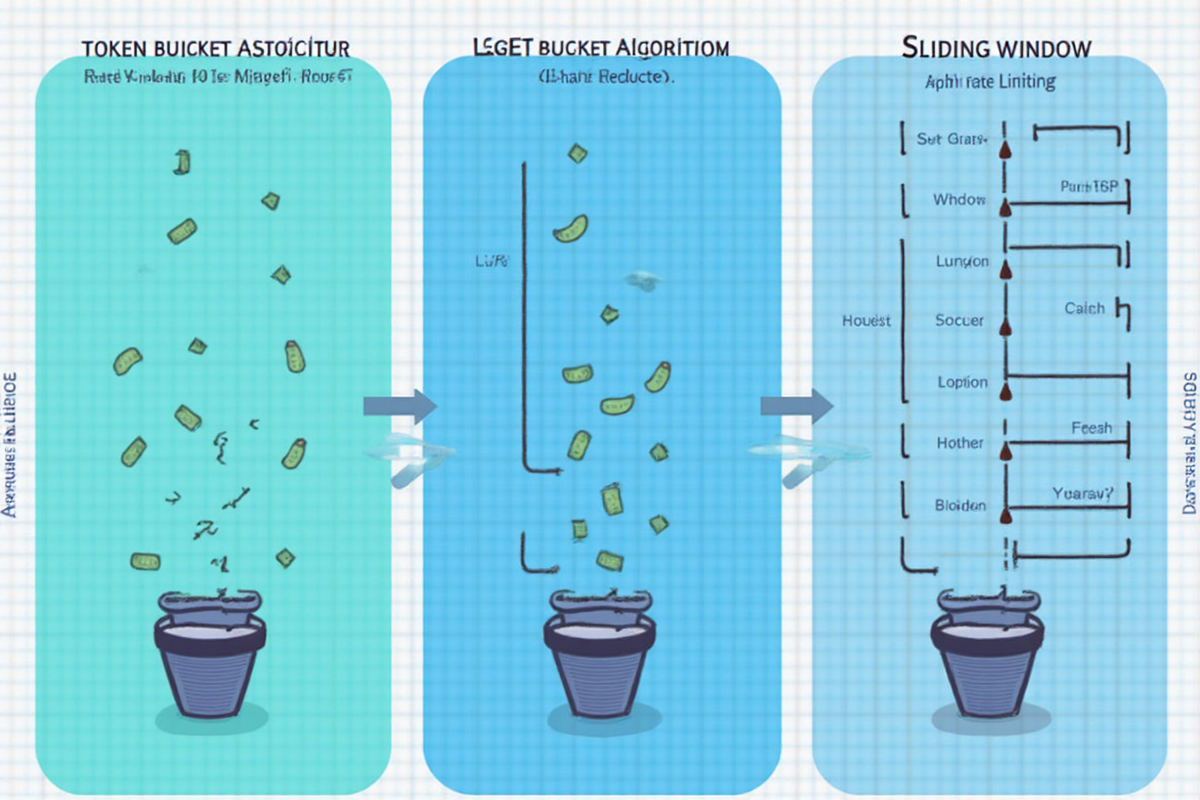
API 限流算法详解:令牌桶、漏桶与滑动窗口的完整实战指南
前言
在分布式系统中,限流(Rate Limiting) 是保障系统稳定性和可用性的关键技术。当面对突发流量或恶意攻击时,限流能够保护后端服务不被 overwhelm,确保核心业务持续可用。
本教程将深入讲解三种经典的限流算法:令牌桶(Token Bucket)、漏桶(Leaky Bucket) 和 滑动窗口(Sliding Window),从原理到实现,从配置到应用,为你提供一套完整的限流解决方案。
无论你是后端开发者、架构师,还是对系统稳定性感兴趣的技术人员,都能从中获得实战价值。
—
第一章:限流基础概念篇
1.1 什么是限流?
限流 是一种控制请求速率的技术,通过在单位时间内限制处理请求的数量,防止系统过载。
限流的核心价值:
- 保护后端服务:避免突发流量冲垮服务器
- 保障服务质量:确保正常用户获得稳定的响应
- 防御恶意攻击:限制恶意用户的请求频率
- 成本优化:避免因过度调用第三方 API 产生的高额费用
1.2 限流的常见场景
1. 用户层面
- 防止恶意刷接口
- 限制免费 API 调用次数
- 会员等级区分
- 系统层面
- 保护数据库连接池
- 控制下游服务调用频率
- 防止雪崩效应
- 业务层面
- 限制验证码发送频率
- 控制下单接口调用
- 防止内容刷量
1.3 限流 vs 限并发
| 对比项 | 限流(Rate Limiting) | 限并发(Concurrency Limiting) |
|---|---|---|
| 定义 | 单位时间内允许的最大请求数 | 同时处理的最大请求数 |
| 单位 | 请求/秒、请求/分钟 | 并发连接数 |
| 适用场景 | 控制总流量 | 控制系统负载 |
| 保护目标 | 下游服务 | 系统资源 |
—
第二章:令牌桶算法详解
2.1 原理说明
令牌桶算法 是最流行的限流算法之一。它的核心思想是:
- 系统以恒定速率向桶中添加令牌
- 桶有固定容量,满了之后的令牌会丢失
- 每次请求需要消耗对应数量的令牌
- 如果桶中没有足够令牌,请求被拒绝
- API 接口调用限制
- 验证码发送限制
- 支付接口保护
- 需要允许合理突发的场景
- 需要严格限制峰值的场景
- 无法维护状态的环境
- 请求以任意速度进入桶中
- 桶以恒定速率流出(处理请求)
- 桶满时,新请求被拒绝或排队
- 需要严格限制处理速率的场景
- 数据库写入操作
- 邮件发送队列
- 需要平滑流量的场景
- 需要响应突发流量的场景
- 延迟敏感型服务
- 需要精确控制流量的场景
- API 调用频率限制
- 实时统计需求
- Redis 限流实现
- 结合 Redis 的分布式限流
- 需要精确到毫秒级别的限流
- 需要精确控制每个用户的调用频率
- 支持分布式部署
- 可以精细划分时间窗口
- 数据库写入需要严格控制速率
- 避免突发写入导致性能下降
- 可以缓冲部分请求
- 允许合理的请求突发
- 保护付费 API 不被过度调用
- 实现简单,易于维护
- 理解了限流的基本概念和应用场景
- 深入学习了三种核心算法的原理
- 令牌桶:允许突发,平滑限制
- 漏桶:严格平滑,缓冲请求
- 滑动窗口:精确控制,灵活配置
- 掌握了每种算法的代码实现
- 了解了算法对比和选型建议
- 获得了生产环境实践方案
- 根据业务需求选择合适的算法
- 生产环境建议配合 Redis 实现分布式限流
- 设置合理的监控告警机制
- 定期评估和调整限流阈值
恒定速率添加令牌
↓
┌───────────────┐
│ │
│ 桶 │ ← 容量上限
│ │
└───────┬───────┘
│
↓ 请求获取令牌
消耗令牌
2.2 代码实现示例
“`python
from collections import deque
import time
class TokenBucket:
def __init__(self, rate, capacity):
“””
rate: 每秒添加的令牌数
capacity: 桶的容量
“””
self.rate = rate
self.capacity = capacity
self.tokens = capacity
self.last_update = time.time()
def consume(self, tokens=1):
“””尝试消耗指定数量的令牌”””
now = time.time()
# 计算新增令牌
new_tokens = (now – self.last_update) * self.rate
self.tokens = min(self.capacity, self.tokens + new_tokens)
self.last_update = now
if self.tokens >= tokens:
self.tokens -= tokens
return True
return False
使用示例
bucket = TokenBucket(rate=10, capacity=20) # 每秒 10 个令牌,容量 20
模拟请求
for i in range(25):
if bucket.consume():
print(f”请求 {i+1}: 允许”)
else:
print(f”请求 {i+1}: 拒绝”)
2.3 优点分析
✅ 允许突发流量:桶中有足够的令牌时可以瞬间处理多个请求
✅ 流量平滑:即使请求间隔长,也会被限制在平均速率内
✅ 实现简单:算法逻辑清晰,易于理解和维护
✅ 灵活配置:可以调整速率和容量适应不同场景
2.4 缺点分析
❌ 无法限制峰值:桶满时可以瞬间处理大量请求
❌ 需要维护状态:令牌数量需要实时记录
❌ 分布式实现复杂:需要 Redis 等共享存储
2.5 适用场景
🎯 推荐场景:
🎯 不推荐场景:
---
第三章:漏桶算法详解
3.1 原理说明
漏桶算法 的核心思想是:
请求任意速度流入
↓
┌───────────────┐
│ ~~~~ 桶 │ ← 容量上限
│ ○ ○ │
│ ○ │
└───────┬───────┘
│
↓ 恒定速率流出
处理请求
3.2 代码实现示例
python
import time
class LeakyBucket:
def __init__(self, rate, capacity):
“””
rate: 每秒处理(漏出)的请求数
capacity: 桶的容量(队列长度)
“””
self.rate = rate
self.capacity = capacity
self.queue = []
self.last_leak_time = time.time()
def leak(self):
“””漏出请求”””
now = time.time()
elapsed = now – self.last_leak_time
leaked = int(elapsed * self.rate)
for _ in range(leaked):
if self.queue:
self.queue.pop(0)
else:
break
self.last_leak_time = now
def put(self):
“””尝试放入请求”””
self.leak()
if len(self.queue) < self.capacity: self.queue.append(time.time()) return True return False
使用示例
bucket = LeakyBucket(rate=10, capacity=20) # 每秒处理 10 个请求
模拟突发请求
import random
for i in range(25):
if bucket.put():
print(f”请求 {i+1}: 进入队列”)
else:
print(f”请求 {i+1}: 桶满拒绝”)
time.sleep(random.uniform(0.05, 0.15))
3.3 优点分析
✅ 流量平滑:无论输入如何,输出速率恒定
✅ 防止突发:无法瞬间处理大量请求
✅ 实现简单:队列逻辑清晰
✅ 排队机制:可以缓冲请求而非直接拒绝
3.4 缺点分析
❌ 无法处理突发:即使系统空闲,也无法快速处理积压请求
❌ 延迟增加:请求需要排队等待
❌ 实现复杂:需要队列管理
❌ 状态维护:需要记录队列内容
3.5 适用场景
🎯 推荐场景:
🎯 不推荐场景:
---
第四章:滑动窗口算法详解
4.1 原理说明
滑动窗口算法 通过将时间划分为多个窗口,统计每个窗口内的请求数,从而实现限流。
两种常见实现:
方式一:计数滑动窗口
时间轴:|[0-1s]|[1-2s]|[2-3s]|
窗口滑动: ↗
统计: [5次] [3次] [2次] ← 当前窗口计数
方式二:精细化滑动窗口(推荐)
将每个时间窗口再细分为多个小格子,提高精度:
时间窗口:[ 0-1s ] 细分为 10 个格子
当前时间:0.7s 处
窗口 1: [████████░░] (当前已用 7/10)
窗口 2: [░░░░░░░░░░] (下一个窗口)
滑动时:部分 + 部分
4.2 代码实现示例
python
import time
from collections import deque
class SlidingWindowCounter:
def __init__(self, limit, window_seconds):
“””
limit: 窗口内的最大请求数
window_seconds: 窗口时间(秒)
“””
self.limit = limit
self.window_seconds = window_seconds
self.requests = deque()
def allow_request(self):
“””检查是否允许请求”””
now = time.time()
# 清理过期请求
while self.requests and self.requests[0] <= now - self.window_seconds:
self.requests.popleft()
# 检查是否超过限制
if len(self.requests) < self.limit:
self.requests.append(now)
return True
return False
def get_remaining(self):
"""获取剩余可用请求数"""
now = time.time()
while self.requests and self.requests[0] <= now - self.window_seconds:
self.requests.popleft()
return self.limit - len(self.requests)
使用示例
counter = SlidingWindowCounter(limit=10, window_seconds=1) # 每秒 10 次
测试
for i in range(15):
if counter.allow_request():
print(f”请求 {i+1}: 允许 (剩余: {counter.get_remaining()})”)
else:
print(f”请求 {i+1}: 拒绝”)
time.sleep(0.1)
4.3 精确滑动窗口实现
python
class SlidingWindowLog:
“””使用日志方式的精细化滑动窗口”””
def __init__(self, limit, window_seconds, granularity=10):
“””
limit: 窗口内最大请求数
window_seconds: 窗口时间
granularity: 细分数(精度)
“””
self.limit = limit
self.window_seconds = window_seconds
self.granularity = granularity
self.slot_duration = window_seconds / granularity
self.slots = [0] * granularity
self.current_slot = 0
def allow_request(self):
“””检查并记录请求”””
now = time.time()
current_slot = int(now / self.slot_duration) % self.granularity
# 如果进入新窗口,重置旧数据
if self.current_slot != current_slot:
self._reset_old_slots(current_slot)
self.current_slot = current_slot
# 检查当前窗口计数
total = sum(self.slots)
if total < self.limit:
self.slots[current_slot] += 1
return True
return False
def _reset_old_slots(self, current):
"""重置旧窗口数据"""
self.slots = [0] * self.granularity
使用示例
window = SlidingWindowLog(limit=10, window_seconds=1, granularity=10)
4.4 优点分析
✅ 精度高:可以精细控制时间窗口
✅ 灵活性高:支持多种窗口大小
✅ 实现灵活:计数器、日志、混合等模式
✅ 分布式友好:易于用 Redis 实现
4.5 缺点分析
❌ 内存占用:需要存储请求记录
❌ 复杂度较高:尤其是精细化实现
❌ 并发问题:需要加锁或使用原子操作
4.6 适用场景
🎯 推荐场景:
🎯 优势场景:
---
第五章:三种算法对比与选型
5.1 算法对比表
| 特性 | 令牌桶 | 漏桶 | 滑动窗口 |
|------|--------|------|----------|
| 流量突发性 | ✅ 允许突发 | ❌ 严格平滑 | ⚠️ 可配置 |
| 实现复杂度 | 简单 | 简单 | 中等 |
| 内存占用 | 低 | 中 | 中 |
| 分布式支持 | 需 Redis | 需 Redis | 易实现 |
| 精度 | 中 | 低 | 高 |
| 延迟影响 | 无 | 增加 | 无 |
5.2 场景选择建议
┌─────────────────────────────────────────┐
│ 需要允许突发流量? │
├─────────────────────────────────────────┤
│ 是 → 令牌桶算法 │
│ 否 → 需要严格平滑? │
│ 是 → 漏桶算法 │
│ 否 → 滑动窗口算法 │
└─────────────────────────────────────────┘
5.3 实际应用案例分析
场景 1:API 网关限流
推荐算法:滑动窗口(配合 Redis)
原因:
场景 2:数据库写入保护
推荐算法:漏桶
原因:
场景 3:第三方 API 调用
推荐算法:令牌桶
原因:
---
第六章:生产环境实践
6.1 Redis 实现令牌桶
lua
— limit.lua – Redis 令牌桶脚本
local key = KEYS[1]
local capacity = tonumber(ARGV[1])
local rate = tonumber(ARGV[2])
local requested = tonumber(ARGV[3])
local now = redis.call(‘TIME’)
local current_time = now[1] + now[2]/1000000
local bucket = redis.call(‘HMGET’, key, ‘tokens’, ‘last_update’)
local tokens = tonumber(bucket[1])
local last_update = tonumber(bucket[2])
if tokens == nil then
tokens = capacity
last_update = current_time
end
— 计算新增令牌
local delta = current_time – last_update
local new_tokens = delta * rate
tokens = math.min(capacity, tokens + new_tokens)
— 检查是否可以消费
if tokens >= requested then
tokens = tokens – requested
redis.call(‘HMSET’, key, ‘tokens’, tokens, ‘last_update’, current_time)
redis.call(‘EXPIRE’, key, 3600)
return 1
else
return 0
end
6.2 Nginx 限流配置
nginx
基本限流
http {
# 定义限流区域
limit_req_zone $binary_remote_addr zone=api_limit:10m rate=10r/s;
server {
location /api/ {
# 允许突发 20 个请求
limit_req zone=api_limit burst=20 nodelay;
proxy_pass http://backend;
}
}
}
用户级别限流
http {
limit_req_zone $http_authorization zone=user_limit:10m rate=5r/s;
server {
location /api/ {
limit_req zone=user_limit burst=10;
proxy_pass http://backend;
}
}
}
6.3 Spring Cloud Gateway 限流
java
@Bean
public ReactorExecutorFilter ratelimitFilter() {
return new ReactorExecutorFilter((exchange, chain) -> {
String ip = exchange.getRequest().getRemoteAddress().getAddress().getHostAddress();
// 使用 Redis 实现令牌桶
Boolean allowed = redisTemplate.execute(
luaScript,
Collections.singletonList(“limit:” + ip),
“100”, “10”, “1”
);
if (!allowed) {
return Mono.error(new RateLimitException(“Rate limit exceeded”));
}
return chain.filter(exchange);
});
}
“`
—
总结
通过本教程,你已经全面掌握了 API 限流的核心知识:
最佳实践建议:
限流是系统稳定性的重要保障,掌握这些算法将帮助你构建更加健壮的应用系统!
—
*本文档最后更新时间:2026 年 04 月 27 日*

发表评论